Identifiability and parameterization in VAEs
Alex Lee, 2023-01-31
Well, OK, but do we care if VAE models are unidentifiable?
Unfortunately, models are also poor at learning disentangled representations of data (unsupervised)
Here we define disentanglement (informally) as separating the distinct factors of variation, or that a change in a single factor \(z_i\) should lead to a single factor of the representation \(r(\mathbf{x})\).
Or, using a specific approximation called total correlation:
\(C(X_1, ..., X_n) = D_{KL} [p(X_1, ..., X_n)\ ||\ p(X_1)p(X_2) \cdot p(X_n)]\)
The authors (Locatello et al.) train a variety of VAEs (\(\beta\)-VAE, TC-VAE, DIP-VAE, FactorVAE) on a couple of datasets:





Note that each of these has as “labels” the ground-truth factors of variation.
\(C(X_1, ..., X_n) = D_{KL} [p(X_1, ..., X_n)\ ||\ p(X_1)p(X_2) \cdot p(X_n)]\)
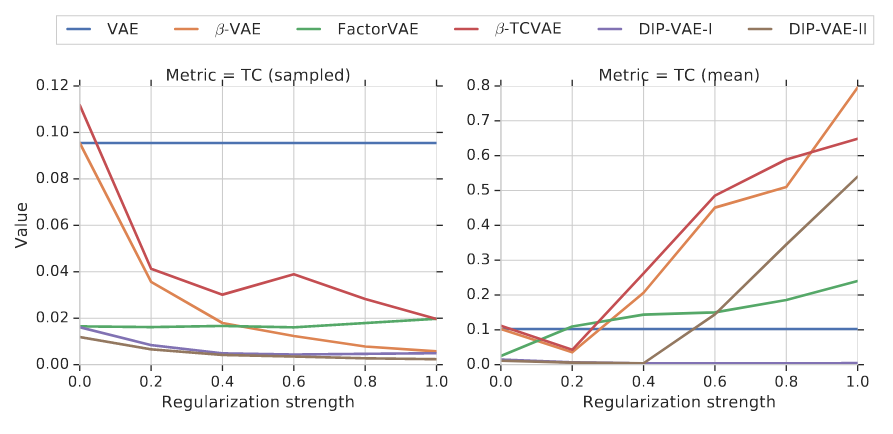
- as regularization goes up (think of \(\beta\)-VAE), \(z\) are disentangled–but only with random sampling
- however, the correlation actually increases when we select the average representation (as we often do)
- disentanglement mildly correlates with downstream accuracy
The salient fact here is that \(\mathbf{u}\) provides the unmixing of \(\mathbf{z}\)
So, then, what is the right variable \(\mathbf{u}\) to condition on, and how should we do it?
There’s a rapidly developing literature in this area, but these two papers present different ideas about this:


To do this, we modify the normal scVI VAE with a spike-and-slab prior:
\[ z_i\ \mid\ a \sim \gamma_i^a\mathrm{Normal}(\mu_i^a, 1) + (1 - \gamma_i^a)\mathrm{Normal}(0,1),\ \mathbf{z} \in \mathbb{R}^d \\ \pi_i^a \sim \mathrm{Beta}(1, K) \\ \gamma_i^a \sim \mathrm{Bernoulli}(\pi_i^a), \]
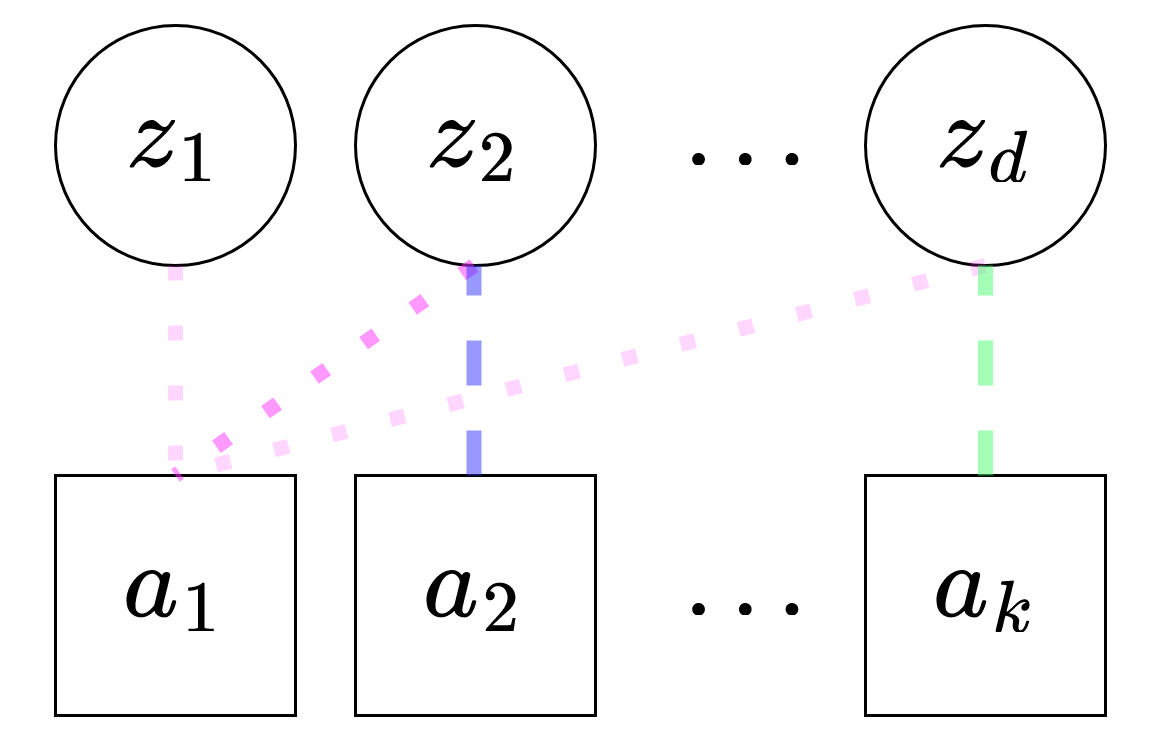
The dotted lines indicate the \(\pi_i^a\)’s learned by the model.
In practice we use a Gumbel-sigmoid to model the Bernoulli.
This formulation gives a identifiability up to linear transformation–stronger than before
This model performs well in simulations of single-cell data
The authors simulate data with this sparse mechanism and try to see if the right \(\pi_i^a\) are learned
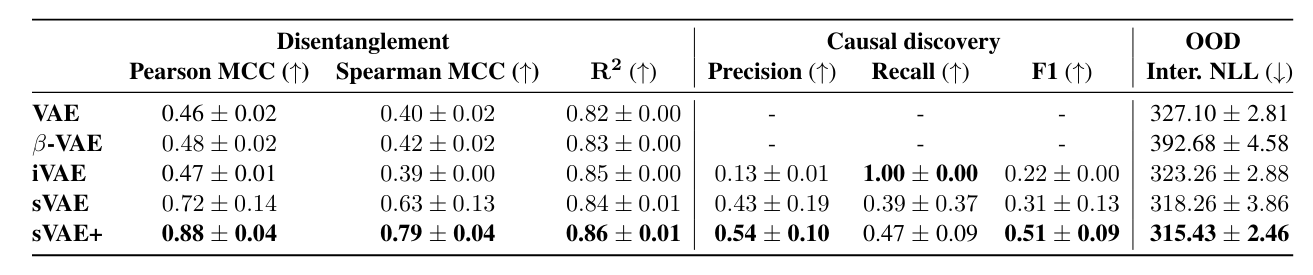
Models were mixed with a small neural network–so I suppose OK that the F1 is quite low-and in general, the iVAE and sVAE were modified in ways that are not exactly correspondent to the original framing to accomodate comparison
Analysis on Replogle (2022) datasets

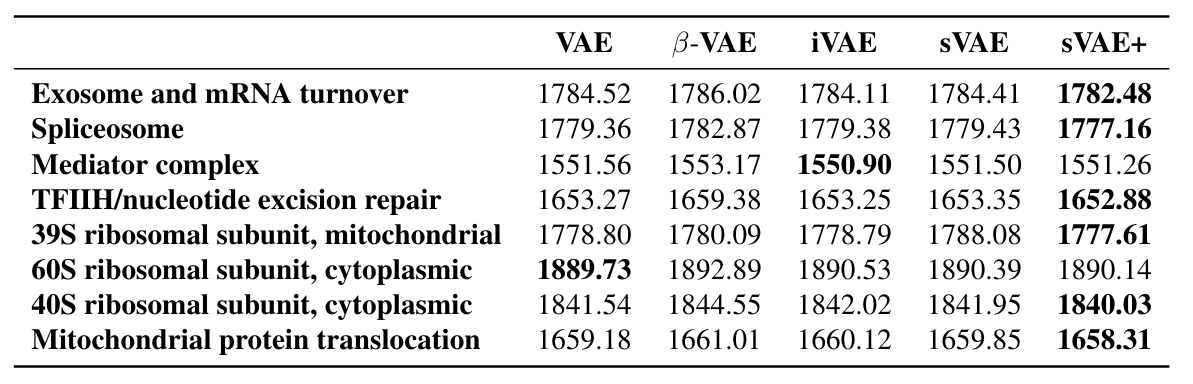
Interventional NLL is highest for sVAE+ on transfer learning task
Hold out sets were defined by manual clustering of perturbations
Taeb et al. focus on interpretability and predictive accuracy
Assumption: \(\mathbf{z}\) can be partitioned into two parts in to an “anti-causal” model:
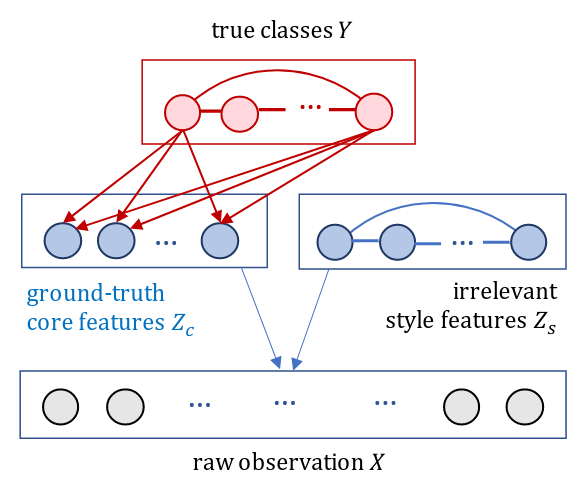
\(\mathbf{z}_c\) and \(\mathbf{z}_s\), where \(s\) denotes “style” features and \(c\) denotes “core” features–only core features are relevant for prediction.
This model has a very different architecture, with two portions
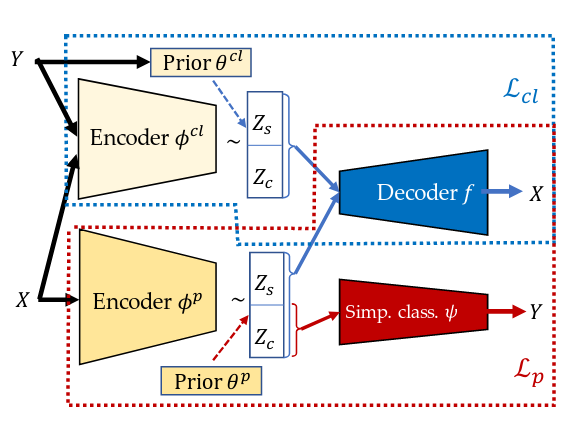
There are two encoders:
- \(\phi_{cl}\), which sees \(\mathbf{Y}\) directly during training
- \(\phi_p\), which only sees \(\mathbf{X}\)
And two decoders:
- \(f\), which actually is used twice every forward pass, once for each set of \(\mathbf{z}\)
- \(\phi\), which simply outputs \(\hat{y}\)
The actual loss then is \(\mathcal{L} = \mathcal{L}_{cl} + \mathcal{L}_{p} - \lambda_n\rho\)
- \(\mathcal{L}_{cl}\) (which is actually two terms, \(f(\phi^p(\mathbf{x}))\) and \(f(\phi^{cl}(\mathbf{x}))\) which helps the \(\mathbf{z}\) converge together and causes “concept learning”
- \(\lambda\rho\) is a group sparsity penalty on the decoder and encoder, separately
Interpretability is provided in form of latent traversal inspection
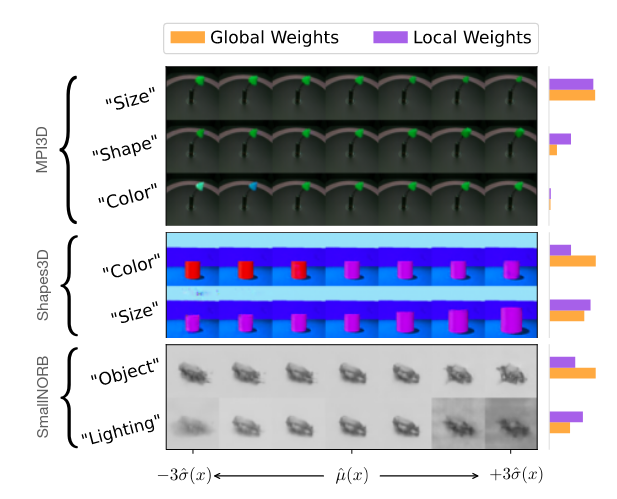
For a given data point, posterior mean is computed and then data points around the source are decoded.
Global vs local weights are from the model or from the data. 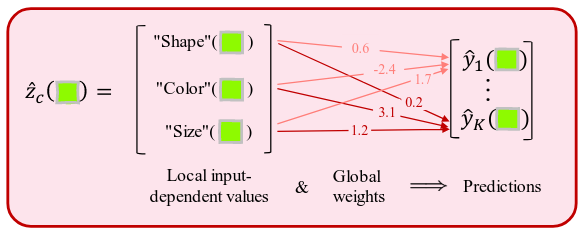
Accuracy is high (>99%) but traversals not incredibly convincing
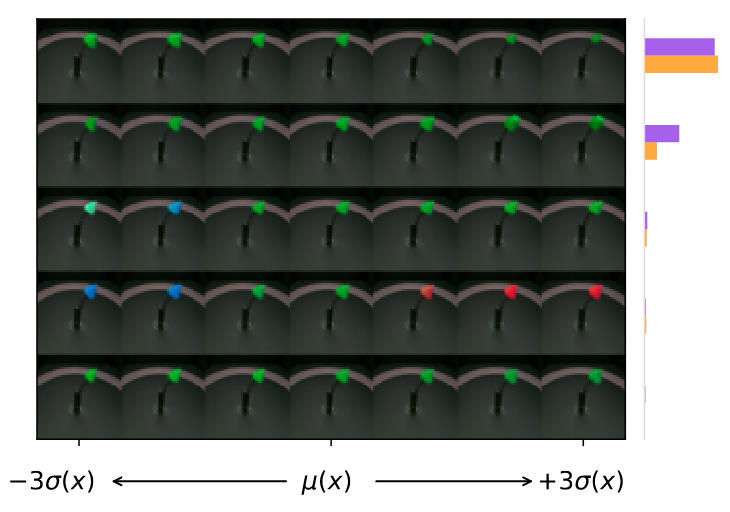
Regularization is also very important; without \(\lambda\) model seems to be more likely to have low-variance / unimportant dimensions.
In addition, for the datasets shown (Shapes3D and MPI3D) there are many labels–performance and ability to recover meaningful variables decreases with number of labels provided
Exploration on chest x-ray dataset
Dataset has 14 classes; CLAP performs at least as well as comparator model (~90% accuracy)
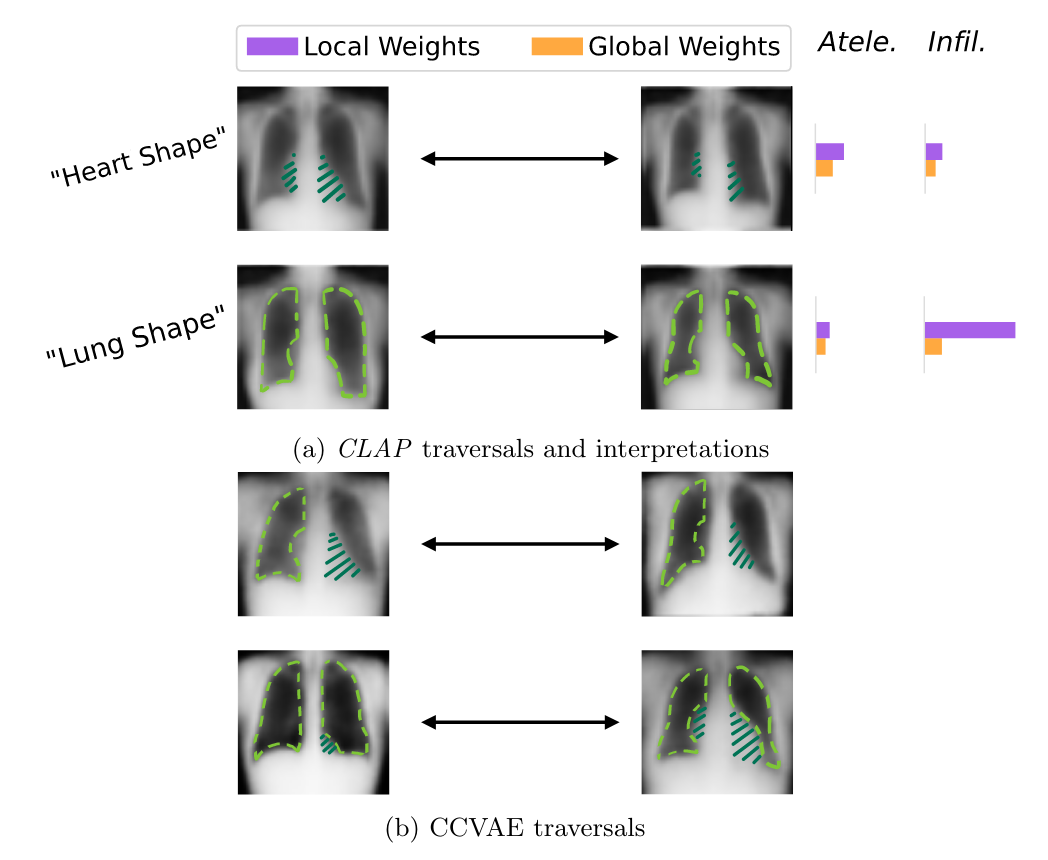
Local vs global weights seem to have some overall relevance for classification (Lung shape feature)
CCVAE does not seem to produce as disentangled features
Authors speculate that low resolution in output images is due to decoder fidelity
Conclusions:
For iVAE, the method focuses on conditional independence of \(\mathbf{u}\) and \(\mathbf{z}\), with no direct parameterization of \(\mathbf{z}\mid\mathbf{x}\)
For sVAE+, focus is on but sparse association of treatments and factors
CLAP the method is much more focused on interpretability, and the anticausal model plays a strong role
